
Hace unos meses hice un pequeño experimento SEO con enlaces internos en esta web: quería conocer qué enlaces puede seguir nuestro todopoderoso Google. Aunque ya hace tiempo desde las primeras pruebas (mayo 2019), no quiero sacar conclusiones equivocadas, por lo que quiero hacer nuevas pruebas en este mismo post de mi blog.
¿En qué consistió el primer experimento?
Este primer experimento pretendía probar distintas formas de enlazar y comprobar si Google era capaz de seguir dicho enlace. Para ello se generó una nueva URL (enlazada en el footer de esta web, sin forzar el rastreo desde Google Search Console), en la cual se encuentran 4 enlaces generados con distintas técnicas, cada cual apuntando a una URL nueva, creada expresamente para cada enlace:
1. Primer enlace
El primer enlace se genera mediante una función jQuery, que actúa sobre una etiqueta <span> con la clase «clica» y que también cuenta con un atributo de datos HTML «data-» que contiene un fragmento de texto con el que la función genera la URL de destino:
Etiqueta HTML
<span class="clica" data-datac="/parte-1-historia.html">Parte 1 de la historia</span>Función jQuery
$('.clica').click(function() {
var d = $(this).data('datac');
location.href="https://comunycaos.com"+d;
} );2. Segundo enlace
El segundo enlace funciona mediante una etiqueta <span> con un evento onclick donde se especifica integramente la URL de destino:
<span class="clica-2" onclick="location.href='https://comunycaos.com/parte2-historia.html'">Parte 2 de la historia</span>3. Tercer enlace
El tercer enlace funciona exactamente igual que el segundo enlace, sólo que se emplea una etiqueta <button> en lugar de una etiqueta <span>. Nuevamente se incluye un evento onclick donde se especifica integramente la URL de destino:
<button class="clica-3" id="tercero" onclick="location.href='https : / / c o m u n y c a o s . c o m / p a r t e 3 - h i s t o r i a . h t m l'">Parte 3 de la historia</button>4. Cuarto enlace (y último del experimento)
El cuarto enlace se construye con una etiqueta <span> que dispone de un evento onclick, el cual ejecuta una función JavaScript que construye la URL de destino. Esta función fue situada en la zona inferior del código de la página.
Al hacer la llamada a la función, se pasa una cadena de texto como variable, en concreto un fragmento de la URL de destino:
Etiqueta HTML
<span class="clica-4" id="cuarto" onclick="enl('no-hay-cuarta')">Parte 4 de la historia</span>Función JavaScript
function enl(x){
location.href="https://comunycaos.com/"+x+".html";
}Hasta este punto, ¿cuáles han sido los resultados del experimento?
Tras aproximadamente 3 semanas, revisar Google Search Console y analizar los logs del servidor con Screaming Frog Log File Analyser puedo decir lo siguiente:
- Google ha rastreado en varias ocasiones la URL que contenía los distintos enlaces.
- De las URLs enlazadas en este experimento, Google sólo ha descubierto la del segundo enlace: (https://comunycaos.com/parte2-historia.html).
- El resto de URLs enlazadas en los enlaces 1, 3 y 4 ni siquiera han sido visitadas por el bot de Google.
¡Ojo!, no saquemos conclusiones antes de tiempo
Antes de sacar conclusiones no debemos perder de vista uno de los hallazgos resultantes del analisis de Google Search Console y SF File Log Analyser:
- Google pasa muy poco por esta web. Y es que más que «Crawl Budget» tengo «K.O. budget». Esto es, Google no gasta mucho tiempo en esta web por su escaso número de URLs y frecuencia de actualización de la misma, lo que puede ser un factor importante a la hora de divagar sobre si Google examinó la URL del experimento con más o menos exhaustividad.
- Además de lo anterior, la URL del experimento era «joven», con escaso contenido y relevancia.
Toca reflexionar: ¿qué creo que ha pasado?
En vista de que el segundo enlace (<span> con onclick) funciona de forma similar al tercer enlace (<button> con onclick), salvo por el tipo de etiqueta HTML, ¿por qué Google sólo ha examinado la URL del segundo enlace?
Si bien sabemos, Google puede rastrear una URL por su mera presencia en el código, sin necesidad de que esté enlazada de alguna forma. En este caso, las URLs del enlace 2 y 3 aparecen integramente en el código.
Teniendo en cuenta esto, también forcé a explorar la URL del experimento desde GSC en diversas ocasiones para comprobar si Google lograba rastrear las URLs enlazadas, aunque sin éxito.
¿Y qué pasa con los enlaces 1 y 4?
Por otra parte, esperaba y comprendo que las URLs de los enlaces 1 y 4 no hayan sido rastreadas. Estos enlaces emplean funciones jQuery y JavaScript y no contienen la URL de forma explícita, sino fragmentos de la URL que es construida mediante las funciones que se detallan en este artículo. Salvo que Google simulase la acción del click, difícilmente podría alcanzar la URL de destino.
Después del primer round, ¿ahora qué?
A día 9 de agosto de 2019, mi teoría es que la escasa relevancia de la web y la URL del experimento han sido causa de que Google no se haya esmerado mucho en explorar el contenido de la misma.
Nueva hipótesis: más relevancia, más atención al contenido.
Ahora pienso probar estos enlaces en otra URL con mayor fuerza, lo cual -posiblemente- haga que Google encuentre al menos la URL del tercer enlace, o esa es mi teoría. ¡El tiempo y Google dirán! Os mantendré informados actualizando esta entrada.
Actualización (10/09/2019): ¡Sin novedad en el frente!
Tras un mes es momento de analizar los hallazgos encontrados. Google sigue sin seguir ni explorar la URL del evento onclick del tercer enlace analizado en este post. Todos los detalles y conclusiones los explico a continuación.
Nueva revisión del experimento
Re-Experimentando
Para revisar si se trataba de un problema de relevancia de la URL original del experimento, seleccioné una de las URLs más relevantes de esta web (WordPress Multisite para SEO) e introduje –como en el experimento original– un «pseudo enlace» creado con una etiqueta <button> que emplea un evento onClick=»location.href=’https://comunycaos.com/parte3-historia.html'», tal que así:
<button style="border: 0px;background-color: #ffffff;" id="tercero" onclick="location.href='https://comunycaos.com/parte3-historia.html'">Parte 3 de la historia</button>Para curarme en salud y evitar que Google pudiese leer la URL del experimento tras escribirla en el post donde explico el experimento, añadí espacios en blanco entre cada letra de la URL que aparecía escrita en dicho post.
Un mes después… ¡A revisar se ha dicho!
Tras un mes desde que comenzara el re-experimento (desde el 9 de agosto al 9 de septiembre de 2019), comencé a analizar los datos de Google Search Console, los datos que arrojaba el comando «site:comunycaos.com» y los logs del servidor de la web. De todo esto he podido concluir lo siguiente:
- En Google Search Console no hay rastro de la URL definida en el pseudo-enlace. Es decir: «https://comunycaos.com/parte3-historia.html»
- El comando «site:comunycaos.com» tampoco daba señales de vida de la URL.
- Los Logs analizados con Screaming Frog Log File Analyzer no mostraban ni un solo «toque» a dicha URL por parte de Bots, ni GoogleBot, ni BingBot, ni nada que se le parezca.
- Los logs analizados muestran que sí se han rastreado de forma periódica las URL del experimento original y la URL de mayor relevancia empleada para la revisión del experimento, ergo, sige sin «tocar a la puerta» de la URL definida en el onclick del <button> definido para el experimento.
In-conclusiones y nueva hipótesis
Después de analizar por enésima vez los logs y comprobar que Google sigue revisitando las URLs que contienen los enlaces de los experimentos, sin llegar a rastrear dichas URLs, la teoría de «falta de relevancia» la dejaré en la reserva.
Por otro lado, tampoco me aventuro a afirmar que Google lee los eventos onclick en algunas etiquetas HTML como <div> o <span>, pero no de <button>.
Hola, Google, ¿me lees?
Mi nueva hipótesis es que Google va a leer la URL de este mismo post. Para ello, nada más publicar esta revisión forzaré la exploración de la misma, para que Google se ponga las pilas cuanto antes. ¿Encontrará por fin Google la URL https://comunycaos.com/parte3-historia.html? ¡Hagan sus apuestas!
Actualización tras las últimas pruebas (21 de octubre de 2019)
En todo el tiempo transcurrido tras esta revisión del experimento y pese a las sucesivas hipótesis que fueron surgiendo, puedo decir que:
- Según logs del servidor, ningún bot de Google ha pasado a visitar la URL «parte3-hstoria.html»
- Como se esperaba, tampoco han sido detectadas las demás URLs: «parte4-historia.html» y «parte1-historia..html».
- En este periodo, pese a haber sido descubierta, explorada e indexada, la URL «parte2-historia.html» tampoco ha sido revisitada por los bots de Google. Es más, para más júbilo de este experimento, en estre transcuros la URL «parte2-historia.html» ha desaparecido del índice de Google y ahora aparece en GSC como «URL rastreada actualmente sin indexar»:
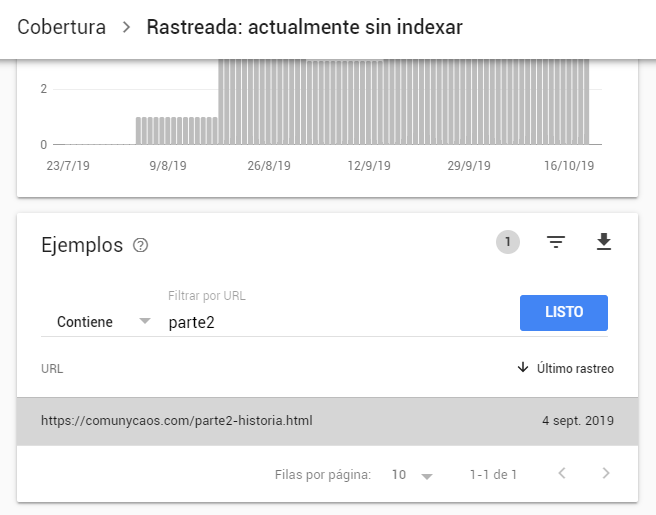
Quizás, como ya apuntaba en los inicios del experimento, la clave sea el volumen y popularidad del sitio. Seguramente en una web cuyo contenido se renueva de manera frecuente y mejor posicionada, obtenga unos resultados bastante diferentes a los que yo he obtenido con este experimento.
¡2ª Actualización ¿in?esperada! (4/12/2019)
¡Sorpresa, sorpresa…! Apenas una semana después de dar por zanjado el experimento y de esbozar ms in-conclusiones, el día 3 de noviembre sonó la campana:

Pues sí, como pude comprobar mediante un comando «site:comunycaos.com» al inicio de diciembre, Google había explorado por primera vez la URL «parte3-historia.html» (publicada allá por el mes de mayo). Tras analizar el log del servidor y revisar la caché de la URL indexada, se confirmó: GoogleBot Mobile había visitado la URL por fin.
¿Cómo la encontró? Buena pregunta. Puedo imaginar que la tuviera previamente «fichada» y en cola para ser explorada, pues el log del 3 de noviembre muestra que el bot de Google sólo accedió a:
- https://comunycaos.com/
- https://comunycaos.com/amp/
- https://comunycaos.com/parte3-historia.html
- Adicionalmente, también accedión a ficheros .css y .js
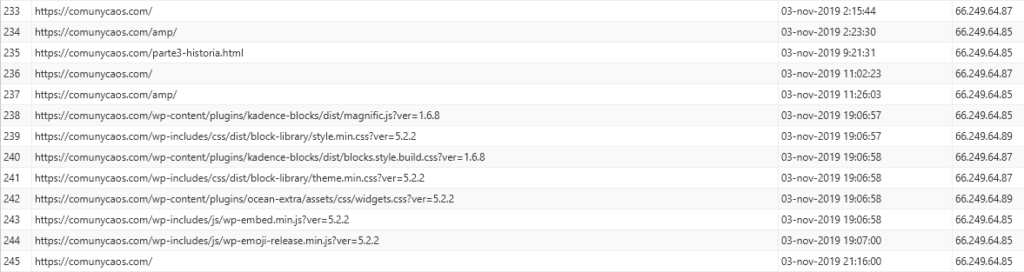
Sea como fuere, este experimento ha dado tantos giros que resulta imposible saber si Google detectó la URL por haberla leído del código del enlace <span> con evento onclick, o símplemente la localizó por el hecho de estar presente como texto plano en las páginas de seguimiento del experimento. En cualquier caso, puedo descartar que dicha URL fuera enlazada (<a>) en este sitio o web externos.
En resumen, que aquí tenemos en Google Search Console el resultado mencionado:

Sólo espero que os haya resultado interesante y os despierte la curiosidad. Si tienes alguna duda o aportación no dudes en darme un toque por Twitter.


